Las muestras gaussianas son utilizadas frecuentemente para modelar
los errores en los modelos de regresión. Estos modelos buscan
explicar un carácter ![]() (considerado como aleatorio) por
carácteres (deterministas)
(considerado como aleatorio) por
carácteres (deterministas)
![]() . Se escoge
una función de regresión
. Se escoge
una función de regresión ![]() , que depende en general de varios
parámetros desconocidos, y se escriben las variables aleatorias
, que depende en general de varios
parámetros desconocidos, y se escriben las variables aleatorias
![]() de la forma:
de la forma:
donde
![]() es una
es una ![]() -tupla de variables aleatorias
independientes y con una misma ley. Los parámetros desconocidos de
-tupla de variables aleatorias
independientes y con una misma ley. Los parámetros desconocidos de
![]() serán estimados por el método de los mínimos cuadrados,
minimizando el
error cuadrático:
serán estimados por el método de los mínimos cuadrados,
minimizando el
error cuadrático:
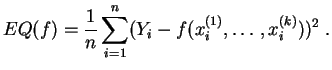
En el caso en que la función ![]() es afín y
es afín y
![]() es
una muestra gaussiana, se puede determinar explícitamente la ley
de los estimadores de mínimos cuadrados y de ella deducir
intervalos de confianza.
es
una muestra gaussiana, se puede determinar explícitamente la ley
de los estimadores de mínimos cuadrados y de ella deducir
intervalos de confianza.
Nosotros solamente consideraremos la regresión lineal simple:
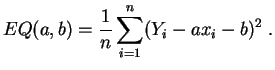
Obtenemos así (ver la sección 2.3) los estimadores de mínimos cuadrados:
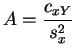 y
y
Estas tres variables aleatorias son estimadores consistentes de
![]() ,
, ![]() y
y ![]() respectivamente. Los dos primeros son
insesgados. La esperanza de
respectivamente. Los dos primeros son
insesgados. La esperanza de ![]() es
es
![]() , por
tanto es asintóticamente insesgado. Se obtiene un estimador
insesgado y consistente de
, por
tanto es asintóticamente insesgado. Se obtiene un estimador
insesgado y consistente de ![]() tomando:
tomando:

La predicción es el primer objetivo de un modelo probabilista. En
el caso de la regresión lineal, si un nuevo individuo es
examinado, con un valor observado ![]() para el carácter
para el carácter ![]() , el
modelo conlleva que el valor
, el
modelo conlleva que el valor ![]() del carácter explicado para
este individuo es una variable aleatoria de ley normal
del carácter explicado para
este individuo es una variable aleatoria de ley normal
![]() . Los parámetros de esta ley tendrán por
estimadores a
. Los parámetros de esta ley tendrán por
estimadores a ![]() y
y ![]() respectivamente.
respectivamente.
El siguiente teorema permite calcular las leyes de estos estimadores y por tanto intervalos de confianza. Lo podemos considerar como una extensión del teorema 3.3.
 sigue
la
ley normal
sigue
la
ley normal
 sigue la
ley de
Student
sigue la
ley de
Student
 sigue la
ley normal
sigue la
ley normal
 sigue la
ley de Student
sigue la
ley de Student
 sigue la
ley de
chi-cuadrado
sigue la
ley de
chi-cuadrado
Estos resultados se emplean de la misma manera que el teorema
3.3 para deducir intervalos de confianza.
Denotamos
![]() ,
,
![]() y
y
![]() los intervalos de dispersión optimales de
nivel
los intervalos de dispersión optimales de
nivel
![]() para las leyes
para las leyes
![]() ,
,
![]() y
y
![]() respectivamente. Los
intervalos de
confianza de nivel
respectivamente. Los
intervalos de
confianza de nivel
![]() correspondientes a los
diferentes incisos del teorema 3.4
son:
correspondientes a los
diferentes incisos del teorema 3.4
son:
![$\displaystyle \left[\,A-z_\alpha\sqrt{\frac{\sigma^2}{ns_x^2}}\;,\;
A+z_\alpha\sqrt{\frac{\sigma^2}{ns_x^2}}\,\right]\;.
$](img465.gif)
![$\displaystyle \left[\,A-t_\alpha\sqrt{\frac{V}{ns_x^2}}\;,\;
A+t_\alpha\sqrt{\frac{V}{ns_x^2}}\,\right]\;.
$](img466.gif)
![$\displaystyle \left[\,Ax_*+B-z_\alpha
\sqrt{\frac{\sigma^2(s_x^2+(x^*-\overlin...
...alpha\sqrt{\frac{\sigma^2(s_x^2+(x^*-\overline{x})^2)}{ns_x^2}}
\,\right]\;.
$](img468.gif)
![$\displaystyle \left[\,Ax_*+B-t_\alpha
\sqrt{\frac{V(s_x^2+(x^*-\overline{x})^2...
...*+B+t_\alpha\sqrt{\frac{V(s_x^2+(x^*-\overline{x})^2)}{ns_x^2}}
\,\right]\;.
$](img469.gif)
![$\displaystyle \left[\,(n-2)\frac{V}{v_\alpha}\;,\;(n-2)\frac{V}{u_\alpha}\,\right]\;.
$](img470.gif)
Si se quiere predecir el valor de
![]() para un nuevo
individuo, habrá que tener en cuenta no solamente el error
cometido al estimar el valor de
para un nuevo
individuo, habrá que tener en cuenta no solamente el error
cometido al estimar el valor de ![]() sino también el de la
varianza
sino también el de la
varianza ![]() de
de ![]() . Esto aumenta la longitud del
intervalo. Veamos el intervalo de predicción de
. Esto aumenta la longitud del
intervalo. Veamos el intervalo de predicción de ![]() , siempre al
nivel
, siempre al
nivel
![]() , cuando no se conoce
, cuando no se conoce ![]() (estimada
por
(estimada
por ![]() ).
).
![$\displaystyle \left[\,Ax_*\!+\!B-t_\alpha
\sqrt{\frac{V((n\!+\!1)s_x^2+(x^*\!-...
...sqrt{\frac{V((n\!+\!1)s_x^2+(x^*\!-\!\overline{x})^2)}{ns_x^2}}
\,\right]\,.
$](img473.gif)
Como ejemplo, consideremos la estatura en centímetros (![]() ) y el
peso en kilogramos (
) y el
peso en kilogramos (![]() ) de
) de ![]() niños de
niños de ![]() años.
años.
Las características numéricas toman los valores siguientes:

Hacer una
regresión lineal quiere decir que pensamos que el peso
debe aumentar, en general, proporcionalmente a la estatura. La
recta de regresión lineal es un modelo de predicción. Para un niño
de estatura dada, daremos un intervalo de peso, considerado como
``normal'', la normalidad se define en referencia al modelo y a
los datos. Estos son los intervalos de predicción de nivel ![]() para diferentes estaturas.
para diferentes estaturas.
Los intervalos de predicción son menos precisos según que el
tamaño de la muestra inicial sea pequeño y que el valor de ![]() esté más lejos de
esté más lejos de
![]() (ver el gráfico
5).
(ver el gráfico
5).
Los resultados precedentes se extienden a las regresiones lineales múltiples. Las expresiones explícitas de los intervalos de confianza son demasiado complicadas para reproducirlas aquí, pero están programadas en todos los logiciales de cálculo estadístico.
