En la base de todo estudio estadístico, hay una población, formada por individuos sobre los cuales se observan carácteres. Para aclarar la idea es más fácil pensar en términos de una población humana. Los individuos son personas y los carácteres observados pueden ser morfológicos (estatura, peso, color de los ojos), fisiológicos (grupo sanguíneo, conteo globular, índice de colesterol) o psicológicos (reacciones en tests, respuestas a una encuesta de opinión). Aunque tomaremos nuestros ejemplos fundamentalmente en poblaciones humanas, hay que mantener en la mente la noción de poblaciones y carácteres más generales. Veamos algunos ejemplos.
Un carácter se llama:
Para facilitar el tratamiento computacional o matemático, se
transforman los datos para
llegar a carácteres cuantitativos a través de una
codificación. Si el carácter inicial es
cualitativo, la codificación será por lo general binaria. El caso
más simple es el de un referendo donde solo hay dos modalidades
codificadas 0 y ![]() . Para un número arbitrario
. Para un número arbitrario ![]() de
modalidades, se podrá codificar por un vector de
de
modalidades, se podrá codificar por un vector de ![]() variables
booleanas: si el valor observado para un individuo es
variables
booleanas: si el valor observado para un individuo es ![]() , el
vector asociado a este individuo tiene todas sus componentes nulas
salvo la
, el
vector asociado a este individuo tiene todas sus componentes nulas
salvo la ![]() -ésima que vale
-ésima que vale ![]() . En el caso de un carácter ordinal
frecuentemente se realiza la codificación empleando los primeros
números enteros. Debemos recordar que la codificación es
arbitraria y que los resultados numéricos que se obtienen después
de la codificación pueden depender de ésta. Existen técnicas
específicas para el tratamiento especial de los carácteres
cualitativos y ordinales. Aquí nos limitaremos esencialmente a los
carácteres cualitativos.
. En el caso de un carácter ordinal
frecuentemente se realiza la codificación empleando los primeros
números enteros. Debemos recordar que la codificación es
arbitraria y que los resultados numéricos que se obtienen después
de la codificación pueden depender de ésta. Existen técnicas
específicas para el tratamiento especial de los carácteres
cualitativos y ordinales. Aquí nos limitaremos esencialmente a los
carácteres cualitativos.
La estadística interviene cuando es imposible, o inútil, observar
un carácter sobre el total de la población. Lo observamos entonces
sobre una subpoblación de tamaño reducido esperando extraer
conclusiones que puedan ser generalizadas a toda la población. Si
los datos sobre un carácter cuantitativo se pueden obtener sobre
![]() individuos, el resultado es una
individuos, el resultado es una ![]() -tupla de números, enteros o
decimales
-tupla de números, enteros o
decimales
![]() , que llamamos muestra o
serie estadística, de talla o tamaño
, que llamamos muestra o
serie estadística, de talla o tamaño ![]() . El término de
muestra lo reservamos más bien para el resultado de
. El término de
muestra lo reservamos más bien para el resultado de ![]() experiencias realizadas una independiente de las otras en
condiciones idénticas (lanzamiento de dados, medida del peso de
experiencias realizadas una independiente de las otras en
condiciones idénticas (lanzamiento de dados, medida del peso de
![]() recién nacidos,...). Llamaremos serie
estadística al resultado de
recién nacidos,...). Llamaremos serie
estadística al resultado de ![]() experiencias que no son intercambiables entre sí. El caso más
frecuente es el en que la población está formada por instantes
sucesivos (lectura diaria de temperaturas, cantidad mensual de
desempleados,...). Hablamos entonces de
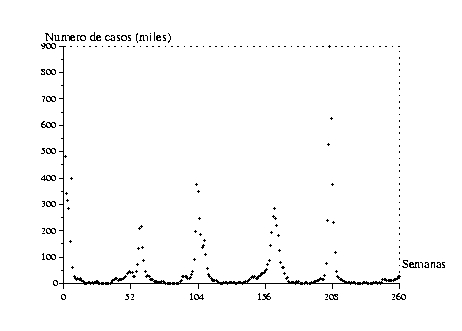
serie
cronológica
(figura 1).
experiencias que no son intercambiables entre sí. El caso más
frecuente es el en que la población está formada por instantes
sucesivos (lectura diaria de temperaturas, cantidad mensual de
desempleados,...). Hablamos entonces de
serie
cronológica
(figura 1).
En general diferenciamos los carácteres discretos (aquellos que toman pocas modalidades diferentes) de los carácteres continuos (para los cuales todos los valores observados son a priori diferentes). La frontera entre continuo y discreto es menos clara en la práctica que en la teoría. Toda recolección de datos se hace con una cierta precisión, y en una unidad de medida dada. Si una estatura se mide con una precisión del orden de un centímetro, todo valor que corresponda a una cantidad inferior a un centímetro no contiene ninguna información y debe ser eliminado. Esto significa que la estatura en centímetros es un valor entero, por tanto un carácter discreto, aún si lo modelamos por una ley normal que es una ley continua. Por otra parte, diversas técnicas estadísticas (histogramas, distancia de chi-cuadrado) requieren reagrupar los datos en clases, lo que los convierte en discretos, cuyas modalidades son las diferentes clases.
Una vez recogida, la muestra
![]() se presenta como
una lista poco leíble, cuya principal carácterística es una mayor
o menor variabilidad. El tratamiento estadístico consiste en
estudiar esta variabilidad, para extraer la información que ella
contiene, a saber lo que es generalizable a la población total.
Las técnicas de la estadística descriptiva tendrán como objetivo
comprimir la muestra, resumirla a partir de cantidades calculadas
y representaciones gráficas, con el fin de extraer la información
que ella contiene.
se presenta como
una lista poco leíble, cuya principal carácterística es una mayor
o menor variabilidad. El tratamiento estadístico consiste en
estudiar esta variabilidad, para extraer la información que ella
contiene, a saber lo que es generalizable a la población total.
Las técnicas de la estadística descriptiva tendrán como objetivo
comprimir la muestra, resumirla a partir de cantidades calculadas
y representaciones gráficas, con el fin de extraer la información
que ella contiene.
No se trata una muestra sin tener una pregunta precisa que
hacerle. Dada una muestra de las estaturas de muchachas de 18 años,
el tratamiento no será el mismo si uno es un nutricionista que
busca estudiar la influencia de la alimentación sobre el
crecimiento, o un fabricante de ropa que busca cómo hacer sus
patrones.
La palabra '' estadística'' tiene dos sentidos diferentes:
A veces, se llama tanbién ''estadística'' a una función de los datos, como la media o la varianza; preferimos usar la palabra ''estadígrafo''.