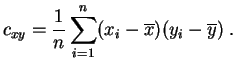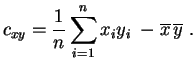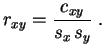Si dos carácteres cuantitativos ![]() e
e ![]() son
medidos en
son
medidos en ![]() individuos, podemos considerar a la
muestra
bidimensional como una
nube de
individuos, podemos considerar a la
muestra
bidimensional como una
nube de ![]() puntos en
puntos en
![]() . Diferentes
carácterísticas estadísticas permiten resumir la información
contenida en su forma. Si
. Diferentes
carácterísticas estadísticas permiten resumir la información
contenida en su forma. Si
![]() e
e
![]() denotan
a las medias empíricas de los dos carácteres, el punto
denotan
a las medias empíricas de los dos carácteres, el punto
![]() es el centro de gravedad de la nube.
Las varianzas empíricas
es el centro de gravedad de la nube.
Las varianzas empíricas ![]() y
y ![]() evidencian la dispersión
de abscisas y de ordenadas. Para ir más allá en la descripción,
hay que calcular la
covarianza.
evidencian la dispersión
de abscisas y de ordenadas. Para ir más allá en la descripción,
hay que calcular la
covarianza.
Esta definición extiende la de la
varianza en la medida en que
![]() . La
covarianza es simétrica (
. La
covarianza es simétrica (
![]() ) y
bilineal: si
) y
bilineal: si ![]() y
y ![]() son dos muestras de tamaño
son dos muestras de tamaño ![]() ,
, ![]() y
y
![]() dos números reales y denotamos
dos números reales y denotamos
![]() , entonces:
, entonces:
La covarianza es la media de los productos menos el producto de las medias.
Demostración:
Basta desarrollar los productos:
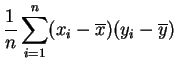 |
|||
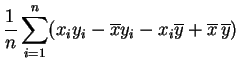 |
|||
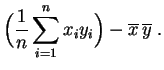 |
La covarianza se compara al producto de las desviaciones estándar empleando la desigualdad de Cauchy-Schwarz.
Demostración:
Sea ![]() un número real arbitrario. Calculemos la
varianza de
un número real arbitrario. Calculemos la
varianza de ![]() :
:
A partir de la desigualdad 3.1, parece natural dividir la covarianza por el producto de las desviaciones estándar, para así definir el coeficiente de correlación (las desviaciones estándar se suponen no nulas).
Cualesquiera que sean las unidades y los ordenes de magnitud de
![]() e
e ![]() , el coeficiente de correlación es un número sin
unidades, comprendido entre
, el coeficiente de correlación es un número sin
unidades, comprendido entre ![]() y
y ![]() . Expresa la mayor o menor
dependencia lineal entre
. Expresa la mayor o menor
dependencia lineal entre ![]() e
e ![]() o, geométricamente, el
mayor o menor aplastamiento de la nube de puntos. Hemos visto que
la desigualdad 3.1 no podía ser una igualdad salvo
si
o, geométricamente, el
mayor o menor aplastamiento de la nube de puntos. Hemos visto que
la desigualdad 3.1 no podía ser una igualdad salvo
si ![]() es constante o si
es constante o si ![]() es de la forma
es de la forma ![]() . Si
. Si ![]() es
positivo, el coeficiente de correlación de
es
positivo, el coeficiente de correlación de ![]() con
con ![]() es igual
a
es igual
a ![]() , es igual a
, es igual a ![]() si
si ![]() es negativo. Un coeficiente de
correlación nulo o cercano a 0 significa que no hay relación
lineal entre los carácteres, pero no conlleva ninguna noción
de independencia más general. Consideremos, por ejemplo, las dos
muestras:
es negativo. Un coeficiente de
correlación nulo o cercano a 0 significa que no hay relación
lineal entre los carácteres, pero no conlleva ninguna noción
de independencia más general. Consideremos, por ejemplo, las dos
muestras:
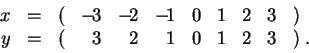
Cuando el coeficiente de correlación está cerca de ![]() o
o ![]() ,
los carácteres se dicen que están ''fuertemente correlados''.
Hay que tener cuidado con la confusión frecuente entre correlación
y causalidad. Que dos fenómenos estén correlados no implica,
de ninguna manera, que uno sea causa del otro. Es muy frecuente
que una correlación fuerte indica que los dos carácteres dependen
de un tercero que no ha sido medido. Este tercer carácter se llama
''factor de confusión''. Que exista una fuerte correlación entre la
recaudación de impuestos en Inglaterra y la criminalidad en el
Japón, indica que ambos están ligados al aumento global de la
población. El precio del trigo y la población de roedores están
negativamente correlados, porque ambos dependen del nivel
de la cosecha de trigo. Puede ser que una fuerte correlación
exprese una verdadera causalidad, como entre el número de
cigarrillos que se fuma al día y la aparición de un cáncer de
pulmón. Pero no es la estadística la que demuestra la causalidad,
ella permite solamente detectarla. La influencia del consumo del
tabaco en la aparición de un cáncer de pulmón ha sido
científicamente demostrada en la medida en que se pudieron
analizar los mecanismos fisiológicos y bioquímicos que hacen que
el alquitrán y la nicotina induzcan errores en la reproducción del
código genético de las células.
,
los carácteres se dicen que están ''fuertemente correlados''.
Hay que tener cuidado con la confusión frecuente entre correlación
y causalidad. Que dos fenómenos estén correlados no implica,
de ninguna manera, que uno sea causa del otro. Es muy frecuente
que una correlación fuerte indica que los dos carácteres dependen
de un tercero que no ha sido medido. Este tercer carácter se llama
''factor de confusión''. Que exista una fuerte correlación entre la
recaudación de impuestos en Inglaterra y la criminalidad en el
Japón, indica que ambos están ligados al aumento global de la
población. El precio del trigo y la población de roedores están
negativamente correlados, porque ambos dependen del nivel
de la cosecha de trigo. Puede ser que una fuerte correlación
exprese una verdadera causalidad, como entre el número de
cigarrillos que se fuma al día y la aparición de un cáncer de
pulmón. Pero no es la estadística la que demuestra la causalidad,
ella permite solamente detectarla. La influencia del consumo del
tabaco en la aparición de un cáncer de pulmón ha sido
científicamente demostrada en la medida en que se pudieron
analizar los mecanismos fisiológicos y bioquímicos que hacen que
el alquitrán y la nicotina induzcan errores en la reproducción del
código genético de las células.