Los tratamientos estadísticos se carácterizan por un ir y venir
permanente entre los datos, que son colecciones de cifras medidas,
y los modelos probabilistas que no tienen ninguna realidad física,
pero proveen herramientas para describir la variabilidad de los
datos. En esta manera de pensar, un primer paso consiste en
asociar a la muestra una ley de probabilidad ficticia.
La
distribución
empírica asociada a una muestra es la ley de probabilidad sobre
el conjunto de las modalidades, que afecta a cada observación con
el peso ![]() . La idea es la siguiente. Supongamos que queremos
aumentar artificialmente la cantidad de datos. La forma más simple
sería sacar aleatoriamente nuevos valores a partir de los valores
ya observados, respetando sus frecuencias. En otras palabras, se
simularía la distribución empírica.
. La idea es la siguiente. Supongamos que queremos
aumentar artificialmente la cantidad de datos. La forma más simple
sería sacar aleatoriamente nuevos valores a partir de los valores
ya observados, respetando sus frecuencias. En otras palabras, se
simularía la distribución empírica.
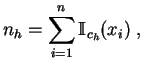
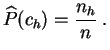
La media, la varianza y la desviación estándar pueden ser vistas
como carácterísticas probabilistas de la distribución empírica.
La
media de la
muestra es la
esperanza de su distribución
empírica.
Para un carácter discreto, la
moda de la distribución
empírica es el valor que tiene la
frecuencia
más alta. Para un
carácter continuo agrupado en clases de amplitudes iguales,
hablamos de clase modal. Una distribución empírica se llama
unimodal si la frecuencia maximal es significativamente
mayor que las otras. Puede ser bimodal o multimodal en
otros casos.
Para estudiar una distribución empírica, la primera etapa consiste en ordenar los datos en orden creciente, es decir escribir sus estadígrafos de orden.
Aquí tenemos como ejemplo a una muestra de tamaño ![]() y sus
y sus ![]() estadígrafos de orden.
estadígrafos de orden.
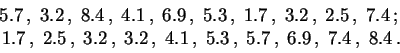
La función de distribución empírica es la función de distribución de la distribución empírica.
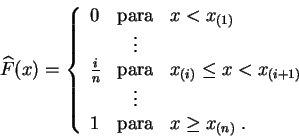
En otras palabras,
![]() es la proporción de los
elementos de la muestra que son menores o iguales a
es la proporción de los
elementos de la muestra que son menores o iguales a ![]() .
.