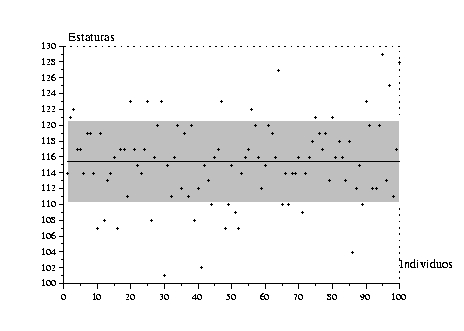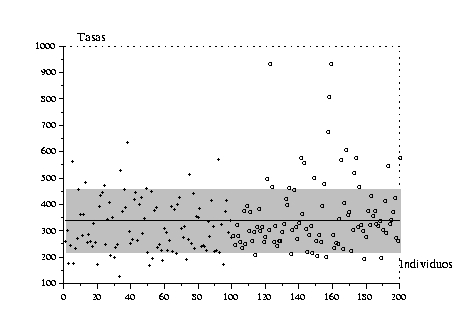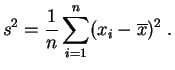
Las nociones de varianza y desviación estándar sirven para cuantificar la variabilidad de una muestra midiendo su dispersión alrededor de la media. La definición es la siguiente:
La ventaja de la desviación estándar sobre la varianza es que se expresa, como la media, en las mismas unidades que los datos. A veces se emplea el coeficiente de variación, que es la razón entre la desviación estándar y la media.
Para medir la dispersión de una muestra alrededor de su media, podríamos hallar más natural otra medida de desviación, por ejemplo la desviación absoluta media, que definiremos más tarde. La razón por la cual la definición que dimos es preferible, se encuentra en la proposición siguiente.
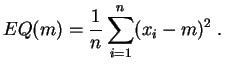
La elección de la varianza para medir la dispersión de
una muestra es por tanto coherente con la elección de la media
empírica como valor central. Más tarde veremos que un fenómeno
análogo ocurre entre la desviación absoluta media y la
mediana.
Demostración:
La función ![]() es un polinomio de grado dos en
es un polinomio de grado dos en ![]() :
:
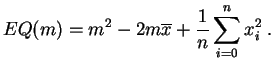
Para el cálculo, en general se emplea un algoritmo que calcula a la vez la media y la varianza, empleando la fórmula que sigue.
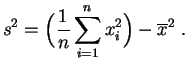
Demostración:
Basta desarrollar los cuadrados en la definición de ![]() :
:
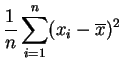 |
|||
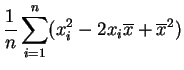 |
|||
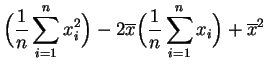 |
|||
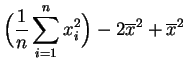 |
|||
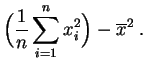 |
En el caso particular de datos binarios,
codificados como 0 y ![]() , la media es la
frecuencia de
, la media es la
frecuencia de ![]() y la
varianza no aporta ninguna información adicional. En efecto si
todos los
y la
varianza no aporta ninguna información adicional. En efecto si
todos los ![]() valen 0 o
valen 0 o ![]() entonces
entonces ![]() y por tanto:
y por tanto:
suma1
![]()
suma2
![]()
Para ![]() de
de ![]() a
a ![]()
suma1
![]() suma1
suma1![]()
suma2
![]() suma2
suma2![]()
finPara
media
![]() suma1
suma1![]()
varianza
![]() suma2
suma2![]() media
media![]() media
media
Para muestras muy grandes hay que prestar atención a la
imprecisión de las sumas acumuladas. Para evitar los errores
se debe trabajar en doble precisión o aún reemplazar el lazo por
dos lazos uno dentro del otro. En algunos casos, podemos
simplificar los cálculos empleando la invarianza por traslación.
Si para todo
![]() ponemos
ponemos
![]() , entonces la
varianza de
, entonces la
varianza de
![]() es
es ![]() . Sea, por ejemplo, la
muestra siguiente:
. Sea, por ejemplo, la
muestra siguiente:
Una vez calculada la media, hemos visto que podíamos centrar los
datos para situarnos en una media nula. La varianza de los datos
centrados es la misma que la de la muestra inicial. Una vez
calculada la varianza, podemos reducir
los
datos
centrados dividiéndolos por la
desviación estándar. Obtenemos así una nueva muestra cuya media es
nula y con varianza igual a ![]() . Hablamos de una muestra
reducida. Observemos que los datos reducidos son números sin
unidades. Por tanto podemos comparar dos muestras reducidas aún si
los datos iniciales no están expresados en las mismas unidades.
. Hablamos de una muestra
reducida. Observemos que los datos reducidos son números sin
unidades. Por tanto podemos comparar dos muestras reducidas aún si
los datos iniciales no están expresados en las mismas unidades.
El inconveniente de la desviación estándar, tal como lo hemos
definido hasta ahora, es que tiene tendencia a subestimar
ligeramente la dispersión de los datos con respecto a su media. La
razón matemática de este defecto está ligada a la noción de
sesgo de un estimador. Podemos tener una idea intuitiva a partir
de un ejemplo simple.
Supongamos que jugamos tres veces a un juego cuya apuesta es ![]() euro. El resultado de cada juego es
euro. El resultado de cada juego es ![]() (gana) o
(gana) o ![]() (pierde).
Si el juego es equitativo debemos esperar que la media valga 0 y
que la desviación estándar sea igual a
(pierde).
Si el juego es equitativo debemos esperar que la media valga 0 y
que la desviación estándar sea igual a ![]() . Sin embargo sobre tres
partidas, los resultados posibles sin contar el orden son los
siguientes.
. Sin embargo sobre tres
partidas, los resultados posibles sin contar el orden son los
siguientes.
![\begin{displaymath}
\begin{array}{\vert crr\vert}
\hline
(x_1,x_2,x_3)&\overl...
...3}&\frac{8}{9}\\ [1ex]
(1,1,1)&1&0\\
\hline
\end{array}
\end{displaymath}](img80.gif)
En ningún caso la desviación estándar empírica puede alcanzar el
valor ![]() . La forma de corregir esta subestimación sistemática es
multiplicar la varianza por
. La forma de corregir esta subestimación sistemática es
multiplicar la varianza por
![]() , donde
, donde ![]() es el tamaño
de la muestra. Hablamos entonces de varianza no
sesgada. Esta es la razón de la
presencia en algunas calculadoras de dos teclas para calcular la
desviación estándar, una marcada
es el tamaño
de la muestra. Hablamos entonces de varianza no
sesgada. Esta es la razón de la
presencia en algunas calculadoras de dos teclas para calcular la
desviación estándar, una marcada ![]() (nuestra
(nuestra ![]() ), la otra
), la otra
![]() que calcula
que calcula
![]() .
.
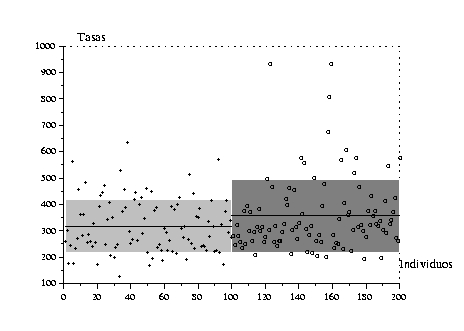
A diferencia de la media, la varianza no es asociativa. Si reagrupamos los datos de una muestra en clases, por ejemplo de acuerdo con un carácter discreto, la varianza se divide en una componente correspondiente a la variabilidad en el interior de las clases y una componente de variabilidad entre las clases.
Supongamos por ejemplo que
los datos recogidos sean dosis hormonales y que las clases
corresponden a tratamientos diferentes aplicados a pacientes.
Queremos saber si la variabilidad observada en los datos se debe
exclusivamente al azar, o si existen efectivamente diferencias
significativas (debidas a los tratamientos) entre las clases. La
media de las varianzas (ponderada por los efectivos) resume la
variabilidad en el interior de las clases, de ahí el nombre de
varianza intra-clases o varianza residual. La varianza
de las medias describe las diferencias entre las clases que pueden
depender de los tratamientos, de ahí el nombre de varianza
inter-clases o varianza explicada. Si los tratamientos
tienen efectivamente una influencia sobre las dosis, esperaríamos
que la varianza explicada sea mayor que la varianza residual. Esta
descomposición de la varianza de una muestra en varianza explicada
y varianza residual es la base de una técnica de análisis de datos
empleada con frecuencia, el
análisis de varianza o ANOVA.
Demostración:
Desarrollemos:
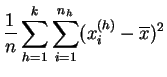 |
|||
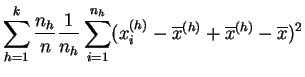 |
|||
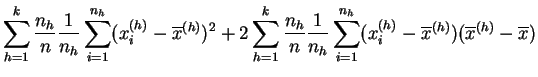 |
|||
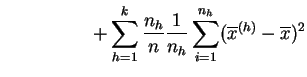 |
|||