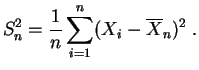En este parrafo, ilustramos las nociones de
estimador, de
consistencia y
de
sesgo
a partir de tres ejemplos: la estimación
de la
varianza, el problema de las preguntas confidenciales y los
conteos por captura-recaptura.
Estimadores de la varianza:
Sea
![]() una muestra de una ley desconocida
una muestra de una ley desconocida ![]() ,
suponiendo que admite momentos de todos los ordenes. Hemos visto
que la
media empírica
,
suponiendo que admite momentos de todos los ordenes. Hemos visto
que la
media empírica
![]() es un
estimador
consistente de la
esperanza.
Es un
estimador insesgado y
su varianza es igual a la varianza de la ley
es un
estimador
consistente de la
esperanza.
Es un
estimador insesgado y
su varianza es igual a la varianza de la ley ![]() , dividida por
, dividida por
![]() . ¿Cómo estimar la
varianza de
. ¿Cómo estimar la
varianza de ![]() ? El estimador más natural es
el siguiente.
? El estimador más natural es
el siguiente.
Si ![]() denota una variable aleatoria de ley
denota una variable aleatoria de ley ![]() ,
, ![]() es
un
estimador consistente de
es
un
estimador consistente de
![]() ,
pero no es un estimador insesgado. En
efecto:
,
pero no es un estimador insesgado. En
efecto:
![$\displaystyle \mathbb {E}[S^2_n] = \frac{n-1}{n}Var[X]\;.
$](img137.gif)
Demostración:
Calculemos primero
![]() .
.
![$\displaystyle \frac{1}{n^2}\mathbb {E}[(X_1+\cdots+X_n)^2]$](img140.gif) |
|||
![$\displaystyle \frac{1}{n^2}
\mathbb {E}\left[\sum_{i=1}^n X_i^2 + \sum_{i=1}^n\sum_{j\neq i} X_iX_j\right]\;.$](img141.gif) |
Por definición de muestra,
![]() son independientes y
de misma ley. Por tanto
son independientes y
de misma ley. Por tanto
![]() y
y
![]() , donde
, donde ![]() es una variable aleatoria
cualquiera de ley
es una variable aleatoria
cualquiera de ley ![]() . Sustituyendo estos valores obtenemos:
. Sustituyendo estos valores obtenemos:
![$\displaystyle \frac{1}{n^2} \Big( n\mathbb {E}[X^2] + n(n-1)
(\mathbb {E}[X])^2)\Big)$](img146.gif) |
|||
![$\displaystyle \frac{1}{n}\mathbb {E}[X^2] + \frac{n-1}{n} (\mathbb {E}[X])^2\;.$](img147.gif) |
![$\displaystyle \frac{1}{n}\mathbb {E}[X_1^2+\cdots+X_n^2]-\frac{1}{n}\mathbb {E}[X^2] -
\frac{n-1}{n} (\mathbb {E}[X])^2)$](img149.gif) |
|||
![$\displaystyle \frac{n-1}{n}\mathbb {E}[X^2] - \frac{n-1}{n} (\mathbb {E}[X])^2)$](img150.gif) |
|||
![$\displaystyle \frac{n-1}{n}Var[X]\;.$](img151.gif) |
Para transformar ![]() en un estimador insesgado, es suficiente
corregir el sesgo por un factor multiplicativo.
en un estimador insesgado, es suficiente
corregir el sesgo por un factor multiplicativo.
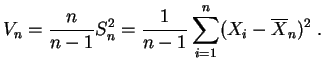
Se puede estimar la
desviación estándar por
![]() o por
o por
![]() . Notemos que en general tanto
. Notemos que en general tanto
![]() como
como
![]() son estimadores sesgados de
son estimadores sesgados de
![]() .
La diferencia entre los dos
estimadores tiende a 0, cuando el tamaño de la muestra tiende a
infinito. No obstante, la mayor parte de las calculadoras proponen
a los dos estimadores de la desviación estándar (teclas
.
La diferencia entre los dos
estimadores tiende a 0, cuando el tamaño de la muestra tiende a
infinito. No obstante, la mayor parte de las calculadoras proponen
a los dos estimadores de la desviación estándar (teclas ![]() y
y
![]() ). Algunos logiciales (en particular
Scilab) calculan el valor de
). Algunos logiciales (en particular
Scilab) calculan el valor de ![]() o
o
![]() ,
otros calculan
,
otros calculan ![]() o
o
![]() . En lo que sigue
emplearemos sobretodo a
. En lo que sigue
emplearemos sobretodo a ![]() , a pesar del inconveniente del
sesgo.
, a pesar del inconveniente del
sesgo.
Preguntas confidenciales:
Ciertos temas abordados en las
encuestas de opinión son bastante íntimos y se corre el riesgo que
las personas encuestadas rehuyan responder francamente al
encuestador, falseando así el resultado. Podemos entonces recurrir
a una astucia que consiste en invertir aleatoriamente las
respuestas. Consideremos una pregunta confidencial para la cual
queremos estimar la probabilidad ![]() de respuestas positivas. El
encuestador pide a cada persona encuestada de lanzar un dado. Si
en el dado sale
de respuestas positivas. El
encuestador pide a cada persona encuestada de lanzar un dado. Si
en el dado sale ![]() , la persona debe responder sin mentir, si no,
debe dar la opinión contraria a la suya. Si el encuestador ignora
cuanto salió en el dado, no podrá saber si la respuesta es veraz o
no, y se puede esperar que la persona encuestada aceptará jugar el
juego. Generalicemos ligeramente la situación sacando, para
cada persona, una variable de
Bernoulli de parámetro
, la persona debe responder sin mentir, si no,
debe dar la opinión contraria a la suya. Si el encuestador ignora
cuanto salió en el dado, no podrá saber si la respuesta es veraz o
no, y se puede esperar que la persona encuestada aceptará jugar el
juego. Generalicemos ligeramente la situación sacando, para
cada persona, una variable de
Bernoulli de parámetro ![]() . Si
el resultado de esta variable es
. Si
el resultado de esta variable es ![]() , la respuesta es veraz, si
no, se invierte la respuesta. Sea
, la respuesta es veraz, si
no, se invierte la respuesta. Sea ![]() el número de personas
encuestadas. El encuestador recoge solamente la
frecuencia
empírica
el número de personas
encuestadas. El encuestador recoge solamente la
frecuencia
empírica ![]() de los ''sí''. La proporción desconocida de los
''sí'' a partir de este procedimiento es
de los ''sí''. La proporción desconocida de los
''sí'' a partir de este procedimiento es
![]() y la frecuencia
y la frecuencia ![]() observada por el
encuestador es un estimador insesgado y consistente de
observada por el
encuestador es un estimador insesgado y consistente de ![]() .
Observemos que si
.
Observemos que si
![]() ,
, ![]() vale
vale ![]() , cualquiera que sea
, cualquiera que sea
![]() . Pero si
. Pero si
![]() , podemos expresar
, podemos expresar ![]() en función de
en función de
![]() :
:
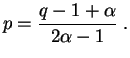
Por tanto podemos proponer como estimador de ![]() a la cantidad
siguiente:
a la cantidad
siguiente:
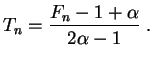
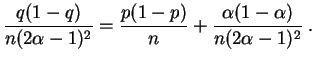
El estimador ![]() es insesgado y su varianza tiende a 0, por
lo tanto es consistente.
es insesgado y su varianza tiende a 0, por
lo tanto es consistente.
Para ![]() fijo, la varianza de
fijo, la varianza de ![]() tiende a infinito cuando
tiende a infinito cuando
![]() tiende a
tiende a ![]() . Ella es minimal si
. Ella es minimal si ![]() o
o ![]() (pero
entonces el procedimiento pierde todo su interés). El problema
consiste entonces en seleccionar un valor de
(pero
entonces el procedimiento pierde todo su interés). El problema
consiste entonces en seleccionar un valor de ![]() que sea
bastante grande, para que la confidencialidad sea creíble, pero lo
suficientemente alejado de
que sea
bastante grande, para que la confidencialidad sea creíble, pero lo
suficientemente alejado de ![]() para no aumentar demasiado la
varianza del estimador. Para el dado, el valor de
para no aumentar demasiado la
varianza del estimador. Para el dado, el valor de ![]() es
es
![]() y el término adicional de la varianza es proporcional a
y el término adicional de la varianza es proporcional a
![]() .
.
Conteos por captura-recaptura:
¿Cómo estimar el número de especies de
insectos que viven en la Tierra, ya que numerosas especies son,
todavía, desconocidas? ¿Cómo conocemos la población de ballenas en
el océano? El conteo por captura-recaptura permite evaluar las
poblaciones para las cuales un censo exhaustivo es imposible. El
método se basa en una idea simple. Consideremos una población de
tamaño ![]() , desconocido. Se toma, en un primer momento, un grupo
de individuos de tamaño
, desconocido. Se toma, en un primer momento, un grupo
de individuos de tamaño ![]() fijo. Estos individuos son censados y
marcados de manera tal que puedan ser reconocidos posteriormente.
Más tarde, se toma un nuevo grupo de tamaño
fijo. Estos individuos son censados y
marcados de manera tal que puedan ser reconocidos posteriormente.
Más tarde, se toma un nuevo grupo de tamaño ![]() y observamos el
número
y observamos el
número ![]() de individuos marcados en este nuevo grupo. Si el
segundo muestreo es independiente del primero, la ley de
de individuos marcados en este nuevo grupo. Si el
segundo muestreo es independiente del primero, la ley de ![]() es la
ley hipergeométrica de parámetros
es la
ley hipergeométrica de parámetros ![]() ,
, ![]() y
y ![]() , de esperanza
, de esperanza
![]() . Podemos esperar que la proporción de individuos
marcados en el segundo grupo esté cercano de la proporción de
individuos marcados en el total de la población,
. Podemos esperar que la proporción de individuos
marcados en el segundo grupo esté cercano de la proporción de
individuos marcados en el total de la población, ![]() . Por tanto
es razonable proponer como estimador de
. Por tanto
es razonable proponer como estimador de ![]() a la cantidad
siguiente:
a la cantidad
siguiente:
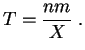
El inconveniente de este estimador es que no está definido si ![]() toma el valor 0, lo que sucede con una probabilidad
estrictamente positiva. Se puede corregir este defecto de dos
maneras. La primera consiste en reemplazar
toma el valor 0, lo que sucede con una probabilidad
estrictamente positiva. Se puede corregir este defecto de dos
maneras. La primera consiste en reemplazar ![]() por
por ![]() , lo cual
no debería falsear mucho los resultados, si los números con que
trabajamos son bastante grandes. Pongamos entonces:
, lo cual
no debería falsear mucho los resultados, si los números con que
trabajamos son bastante grandes. Pongamos entonces:
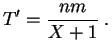
La segunda manera consiste en decidir de rechazar a priori las
muestras para las cuales no se obtengan individuos marcados. Esto
significa reemplazar a ![]() por otra variable aleatoria
por otra variable aleatoria ![]() cuya
ley es la ley condicional de
cuya
ley es la ley condicional de ![]() sabiendo que
sabiendo que ![]() es estrictamente
positiva. Pongamos entonces:
es estrictamente
positiva. Pongamos entonces:
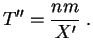
Para valores de ![]() ,
, ![]() y
y ![]() específicos, podemos calcular
numéricamente las esperanzas y las desviaciones estándar de estos
estimadores. La tabla que mostramos a continuación resume los
resultados obtenidos para
específicos, podemos calcular
numéricamente las esperanzas y las desviaciones estándar de estos
estimadores. La tabla que mostramos a continuación resume los
resultados obtenidos para ![]() y diferentes valores de
y diferentes valores de ![]() .
.
Los dos estimadores son sesgados, el primero tiene tendencia a
subestimar el tamaño ![]() de la población, el segundo a
sobreestimarlo. La desviación estándar aumenta más rápidamente que
de la población, el segundo a
sobreestimarlo. La desviación estándar aumenta más rápidamente que
![]() . Es natural que la precisión relativa sea más débil según que
las muestras recogidas sean pequeñas con respecto al tamaño
desconocido de la población.
. Es natural que la precisión relativa sea más débil según que
las muestras recogidas sean pequeñas con respecto al tamaño
desconocido de la población.