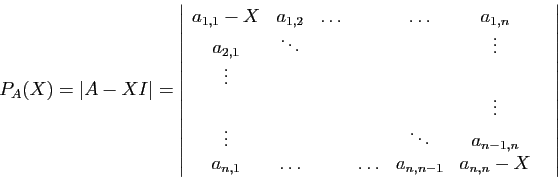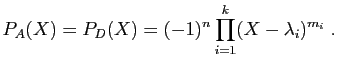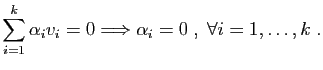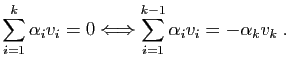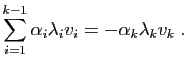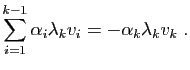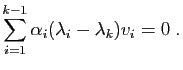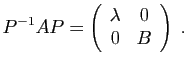Toutes les matrices considérées sont des matrices carrées
à 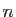 lignes et colonnes, à coefficients dans
lignes et colonnes, à coefficients dans
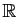 ou
ou
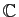 .
Les vecteurs sont identifiés à
des matrices à lignes et
.
Les vecteurs sont identifiés à
des matrices à lignes et 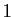 colonne.
colonne.
Une matrice
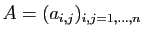 est diagonale si tous ses coefficients en
dehors de la diagonale sont nuls.
est diagonale si tous ses coefficients en
dehors de la diagonale sont nuls.
Elle est donc de la forme :
Pour comprendre le rôle des coefficients diagonaux, supposons tout
d'abord qu'ils sont tous égaux à 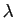 . Dans ce cas,
. Dans ce cas,
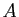 est proportionnelle à la matrice identité :
est proportionnelle à la matrice identité :
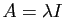 . Pour tout vecteur
. Pour tout vecteur 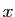 de
de
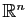 , le vecteur
, le vecteur 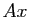 est
proportionnel à :
est
proportionnel à :
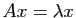 . Multiplier le vecteur
par la matrice revient à le multiplier par le facteur
. Géométriquement, c'est effectuer une homothétie
de rapport .
Supposons maintenant que les coefficients diagonaux soient
quelconques. Considérons une base
. Multiplier le vecteur
par la matrice revient à le multiplier par le facteur
. Géométriquement, c'est effectuer une homothétie
de rapport .
Supposons maintenant que les coefficients diagonaux soient
quelconques. Considérons une base
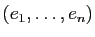 de
, et
examinons l'endomorphisme
de
, et
examinons l'endomorphisme 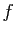 de
, de matrice dans cette
base. Dire que
est diagonale, c'est dire que l'image du vecteur
de
, de matrice dans cette
base. Dire que
est diagonale, c'est dire que l'image du vecteur 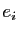 de la base
est
de la base
est
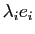 . Si on restreint à la direction ,
est une homothétie de rapport
. Si on restreint à la direction ,
est une homothétie de rapport 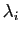 . Si est un vecteur
quelconque de
, s'écrit
. Si est un vecteur
quelconque de
, s'écrit
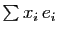 . Son image par
est :
. Son image par
est :
Les matrices diagonales sont
particulièrement simples à manipuler. Voici les propriétés
principales :
- Le déterminant d'une matrice diagonale est le produit des
coefficients diagonaux.
- Multiplier à gauche par une matrice diagonale revient à multiplier
la
 -ième ligne par : si
-ième ligne par : si
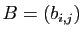 est une matrice
quelconque, alors
est une matrice
quelconque, alors
- Multiplier à droite par une matrice diagonale revient à multiplier
la
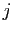 -ième colonne par
-ième colonne par 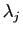 : si
est une matrice
quelconque, alors
: si
est une matrice
quelconque, alors
- Le produit de deux matrices diagonales est une matrice diagonale.
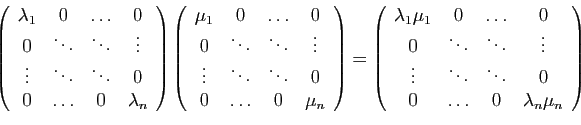
- Si tous les coefficients diagonaux sont non nuls, la matrice est
inversible :
- La puissance
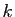 -ième d'une matrice diagonale est :
-ième d'une matrice diagonale est :
Pour une matrice quelconque, les calculs se simplifient à partir
du moment où elle est semblable à une matrice diagonale.
Deux matrices et 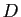 sont
semblables, lorsqu'elles représentent le même endomorphisme dans deux bases
différentes, ou encore, quand il existe une matrice de passage
sont
semblables, lorsqu'elles représentent le même endomorphisme dans deux bases
différentes, ou encore, quand il existe une matrice de passage 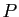 telle que
telle que
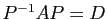 . Par exemple :
. Par exemple :
Définition 1
Une matrice est dite diagonalisable si elle est semblable à une
matrice diagonale.
L'objectif des deux premières sections de ce chapitre
est d'apprendre à diagonaliser une
matrice, quand c'est possible.
Définition 2
Diagonaliser une matrice , c'est trouver une matrice de
passage et une matrice diagonale telles que :
Si
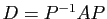 , alors
, alors
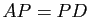 . Mais si est une matrice diagonale, multiplier à
droite par revient à multiplier les vecteurs colonnes de par
les coefficients diagonaux de . Notons
. Mais si est une matrice diagonale, multiplier à
droite par revient à multiplier les vecteurs colonnes de par
les coefficients diagonaux de . Notons 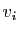 le -ième vecteur
colonne de la matrice et le -ième coefficient
diagonal de . Pour tout
le -ième vecteur
colonne de la matrice et le -ième coefficient
diagonal de . Pour tout
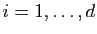 , on doit avoir :
, on doit avoir :
en notant 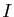 la matrice identité de dimension .
On dit que est un vecteur propre de associé à la
valeur propre .
la matrice identité de dimension .
On dit que est un vecteur propre de associé à la
valeur propre .
Observons que est une valeur propre de si et seulement si
le système
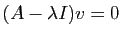 a une solution non nulle.
Voici deux manières
équivalentes de l'exprimer.
a une solution non nulle.
Voici deux manières
équivalentes de l'exprimer.
Définition 4
On appelle polynôme caractéristique de la matrice , et
on note 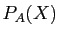 le déterminant de la matrice
le déterminant de la matrice 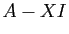 .
.
D'après la forme développée d'un déterminant, est une
somme de produits des termes de la matrice.
Chaque produit est constitué de facteurs qui
sont des termes pris dans des lignes et des colonnes
différentes. Le terme de plus haut degré en 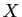 dans le
déterminant
dans le
déterminant 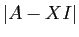 provient du produit des termes qui
contiennent tous , à savoir les coefficients diagonaux :
provient du produit des termes qui
contiennent tous , à savoir les coefficients diagonaux :
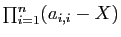 .
Le polynôme caractéristique
est donc de degré : son terme de plus
haut degré est
.
Le polynôme caractéristique
est donc de degré : son terme de plus
haut degré est 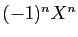 .
Tant que nous y sommes, observons que le terme constant de
est le déterminant de ; c'est aussi le produit
des valeurs propres (comptées avec leurs multiplicités). Le
coefficient du terme de degré
.
Tant que nous y sommes, observons que le terme constant de
est le déterminant de ; c'est aussi le produit
des valeurs propres (comptées avec leurs multiplicités). Le
coefficient du terme de degré 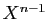 dans est la somme
des termes diagonaux, que l'on appelle la trace de la matrice
; c'est aussi la somme des valeurs propres (toujours
comptées avec leurs multiplicités).
Comme les valeurs propres sont
racines du polynôme caractéristique, une
matrice de dimensions
dans est la somme
des termes diagonaux, que l'on appelle la trace de la matrice
; c'est aussi la somme des valeurs propres (toujours
comptées avec leurs multiplicités).
Comme les valeurs propres sont
racines du polynôme caractéristique, une
matrice de dimensions 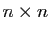 admet au plus valeurs propres
distinctes.
Pour qu'une matrice soit diagonalisable, il faut déjà que son polynôme
caractéristique admette effectivement racines (comptées avec
leurs ordres de multiplicité), donc qu'il soit
scindé. C'est toujours le cas dans
, pas toujours dans
.
Si est une valeur propre, l'ensemble des vecteurs
admet au plus valeurs propres
distinctes.
Pour qu'une matrice soit diagonalisable, il faut déjà que son polynôme
caractéristique admette effectivement racines (comptées avec
leurs ordres de multiplicité), donc qu'il soit
scindé. C'est toujours le cas dans
, pas toujours dans
.
Si est une valeur propre, l'ensemble des vecteurs 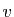 tels
que
, est un sous-espace vectoriel. Par
définition, il contient le vecteur nul, et tous les
vecteurs propres de associés à
. On l'appelle le «sous-espace propre» associé à
.
tels
que
, est un sous-espace vectoriel. Par
définition, il contient le vecteur nul, et tous les
vecteurs propres de associés à
. On l'appelle le «sous-espace propre» associé à
.
Définition 5
Soit une valeur propre, on appelle sous-espace propre
associé à l'espace vectoriel
Démonstration : Remarquons qu'un même vecteur propre ne peut être
associé qu'à une seule valeur propre. Par conséquent,
deux sous-espaces propres associés à deux valeurs
propres distinctes ont une intersection
réduite au vecteur nul : les sous-espaces propres sont en
somme directe.
Supposons que soit diagonalisable :
, mais aussi
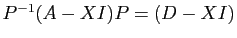 . Les propriétés générales des
déterminants font que
. Les propriétés générales des
déterminants font que
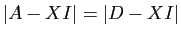 : le polynôme
caractéristique de et celui de sont les mêmes :
: le polynôme
caractéristique de et celui de sont les mêmes :
Or le polynôme caractéristique de est le produit des termes
diagonaux. Cela signifie que pour tout
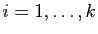 , exactement
, exactement
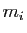 termes diagonaux de sont égaux à .
Il existe donc vecteurs colonnes de qui sont
des vecteurs propres de , associés à la valeur propre
. Comme ces vecteurs forment une famille libre,
la dimension du sous-espace propre associé est au moins égale à
. Comme
termes diagonaux de sont égaux à .
Il existe donc vecteurs colonnes de qui sont
des vecteurs propres de , associés à la valeur propre
. Comme ces vecteurs forment une famille libre,
la dimension du sous-espace propre associé est au moins égale à
. Comme
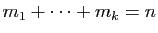 , et que les
sous-espaces propres sont en somme directe, chacun est de
dimension exactement et leur somme directe est
.
Réciproquement, si pour tout le sous-espace propre associé à
est de dimension , alors leur somme directe est
: on peut constituer une base de
en choisissant une
base de vecteurs dans chaque sous-espace propre.
, et que les
sous-espaces propres sont en somme directe, chacun est de
dimension exactement et leur somme directe est
.
Réciproquement, si pour tout le sous-espace propre associé à
est de dimension , alors leur somme directe est
: on peut constituer une base de
en choisissant une
base de vecteurs dans chaque sous-espace propre. La mauvaise nouvelle est que toutes les matrices ne sont pas
diagonalisables. La bonne nouvelle est que celles que vous
rencontrerez, entreront souvent dans l'une des catégories
couvertes par les deux théorèmes suivants : valeurs propres toutes
distinctes, ou bien matrices symétriques.
La mauvaise nouvelle est que toutes les matrices ne sont pas
diagonalisables. La bonne nouvelle est que celles que vous
rencontrerez, entreront souvent dans l'une des catégories
couvertes par les deux théorèmes suivants : valeurs propres toutes
distinctes, ou bien matrices symétriques.
Théorème 2
Soit une matrice admettant
valeurs propres toutes distinctes. Alors est diagonalisable.
Démonstration : Nous allons montrer par récurrence sur que si
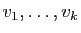 sont des vecteurs propres associés à des valeurs propres
sont des vecteurs propres associés à des valeurs propres
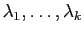 toutes distinctes, alors
toutes distinctes, alors
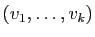 est une famille libre :
est une famille libre :
C'est vrai pour 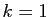 , puisque par définition un vecteur propre est
non nul. Supposons la propriété vraie à l'ordre
, puisque par définition un vecteur propre est
non nul. Supposons la propriété vraie à l'ordre
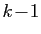 . Soient
des valeurs propres
distinctes deux à deux et
des vecteurs propres
associés. Supposons :
. Soient
des valeurs propres
distinctes deux à deux et
des vecteurs propres
associés. Supposons :
En multipliant à gauche par la matrice , on obtient :
Mais aussi :
Soit en soustrayant les deux équations :
D'après l'hypothèse de récurrence à l'ordre , ceci
entraîne que pour tout
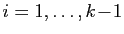 ,
,
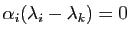 , donc
, donc
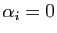 , puisque
, puisque
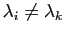 . Mais alors nécessairement
. Mais alors nécessairement
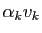 est nul, donc
est nul, donc
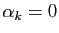 puisque le vecteur propre
puisque le vecteur propre 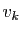 est non
nul.
Supposons qu'une matrice admette valeurs propres toutes distinctes
est non
nul.
Supposons qu'une matrice admette valeurs propres toutes distinctes
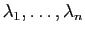 . Pour
. Pour
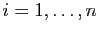 , choisissons un
vecteur propre associé à . D'après ce qui précède
, choisissons un
vecteur propre associé à . D'après ce qui précède
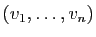 est une famille libre de
, donc une base.
est une famille libre de
, donc une base.
Théorème 3
Soit
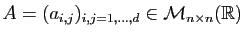 une matrice symétrique :
une matrice symétrique : 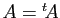 . Alors :
. Alors :
- toutes les valeurs
propres de sont réelles ;
- est diagonalisable ;
- on peut choisir comme base de vecteurs propres une base
telle que la matrice de passage vérifie
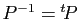 (une
telle base est dite orthonormée).
(une
telle base est dite orthonormée).
Le fait d'avoir une base orthonormée permet d'écrire l'inverse de
la matrice de passage sans calcul supplémentaire (car
). Ce théorème est un cas particulier d'un résultat plus
général, pour une matrice à valeurs
complexes qui est hermitienne, c'est-à-dire telle que
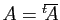 , soit
, soit
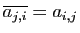 , où
, où
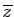 désigne le conjugué du nombre
complexe
désigne le conjugué du nombre
complexe 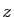 . Les valeurs propres d'une matrice hermitienne
sont réelles, la
matrice est diagonalisable et
il existe une matrice de vecteurs propres unitaire, à savoir
telle que
. Les valeurs propres d'une matrice hermitienne
sont réelles, la
matrice est diagonalisable et
il existe une matrice de vecteurs propres unitaire, à savoir
telle que
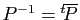 .
Démonstration : Soit un vecteur non nul de
.
Démonstration : Soit un vecteur non nul de
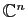 . Considérons le produit :
. Considérons le produit :
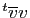 . C'est la somme des modules des coordonnées de
, à savoir un réel strictement positif.
Soit une racine (dans
) de , et soit
un vecteur propre associé à la valeur propre
. Donc :
. C'est la somme des modules des coordonnées de
, à savoir un réel strictement positif.
Soit une racine (dans
) de , et soit
un vecteur propre associé à la valeur propre
. Donc :
Prenons le conjugué de la transposée de ce même produit
(rappelons que
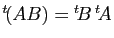 ).
).
puisque est symétrique. Donc
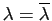 : la valeur propre est
réelle.
Considérons l'ensemble des vecteurs orthogonaux à :
: la valeur propre est
réelle.
Considérons l'ensemble des vecteurs orthogonaux à :
L'ensemble 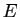 est le noyau d'une application linéaire de rang
(car est non nul). C'est donc un sous-espace vectoriel de
,
de dimension
est le noyau d'une application linéaire de rang
(car est non nul). C'est donc un sous-espace vectoriel de
,
de dimension 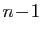 . Soit
. Soit 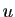 un vecteur de :
un vecteur de :
Donc 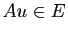 (on dit que est stable par ).
Nous admettrons ici que dans tout espace vectoriel de dimension finie, il
est possible de choisir une base orthormale (par exemple
grâce au procédé d'orthogonalisation de Gram-Schmidt, vu dans un
autre chapitre).
Soit
(on dit que est stable par ).
Nous admettrons ici que dans tout espace vectoriel de dimension finie, il
est possible de choisir une base orthormale (par exemple
grâce au procédé d'orthogonalisation de Gram-Schmidt, vu dans un
autre chapitre).
Soit
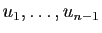 une base orthonormale de .
Quitte à diviser par
une base orthonormale de .
Quitte à diviser par
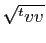 ,
on peut supposer que
,
on peut supposer que 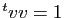 . Par construction,
. Par construction,
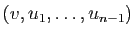 est donc une base orthonormale de
. Notons la
matrice de ses vecteurs colonnes :
. Au travers du
changement de base de matrice de passage , est transformée en
une matrice diagonale par blocs :
est donc une base orthonormale de
. Notons la
matrice de ses vecteurs colonnes :
. Au travers du
changement de base de matrice de passage , est transformée en
une matrice diagonale par blocs :
En effet, la première colonne est nulle après le premier terme car
est un vecteur propre associé à . La première ligne
est nulle après le premier terme car est stable par : les
images de
appartiennent à .
De plus :
de sorte que
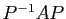 est symétrique, donc
est symétrique, donc 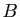 l'est aussi. D'où le
résultat, par récurrence sur .
l'est aussi. D'où le
résultat, par récurrence sur .
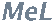 © UJF Grenoble, 2011
Mentions légales
© UJF Grenoble, 2011
Mentions légales

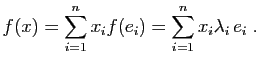
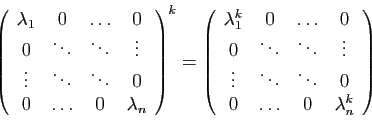
![\begin{displaymath}
\stackrel{
\underbrace{
\left(
\begin{array}{rrr}
\frac{1}{2...
...& 0 [2ex]
0&-1& 0 [2ex]
0&0& 2
\end{array}\right)
}}{D}
\end{displaymath}](img39.gif)