La
función cuantil de una ley de probabilidad es la inversa
(generalizada) de su
función de distribución. Si ![]() denota la
función de distribución, la función cuantil
denota la
función de distribución, la función cuantil ![]() es la función que
a
es la función que
a
![]() hace corresponder:
hace corresponder:
La función cuantil empírica de una muestra es la función cuantil de su distribución empírica.
![$\displaystyle \forall u\in ]\frac{i-1}{n},\frac{i}{n}]\;,\quad
\widehat{Q}(u) = x_{(i)}\;.
$](img134.gif)
|
|
|
|
|
|
|
|
La mediana es el valor central de la muestra: hay tantos valores inferiores a ella como valores superiores a ella. Si la distribución empírica de la muestra es poco disimétrica, como por ejemplo para una muestra simulada a partir de una ley uniforme o normal, la media y la mediana están cercanas. Si la muestra es asimétrica, con una distribución muy dispersa hacia la derecha, la mediana podrá ser mucho más pequeña que la media. A diferencia de la media, la mediana no es sensible a los valores aberrantes. Ella satisface una propiedad de optimalidad con respecto a la desviación absoluta media.
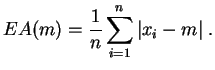
Demostración:
Para evitar complicar las notaciones, supondremos que los valores
![]() son todos diferentes. El gráfico de la función
son todos diferentes. El gráfico de la función ![]() está
formado por segmentos de rectas. Sobre el intervalo
está
formado por segmentos de rectas. Sobre el intervalo
![]() , ella vale:
, ella vale:
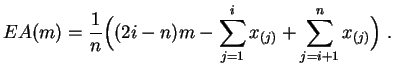
Hay algo arbitrario en la definición de la
función
cuantil
para una distribución empírica: para todos los puntos del
intervalo
![]() , la
función de distribución vale
, la
función de distribución vale
![]() . Son sobre todo razones teóricas las que nos hacen
seleccionar a
. Son sobre todo razones teóricas las que nos hacen
seleccionar a ![]() en lugar de otro punto como valor de
en lugar de otro punto como valor de
![]() . Puede ser una selección bastante mala en la
práctica. Consideremos la muestra siguiente, de tamaño
. Puede ser una selección bastante mala en la
práctica. Consideremos la muestra siguiente, de tamaño ![]() .
.
La mediana, tal y como la hemos definido, vale ![]() . Sin embargo
como valor central se impone claramente el punto medio del
intervalo
. Sin embargo
como valor central se impone claramente el punto medio del
intervalo ![]() , es decir
, es decir ![]() . En el caso de las muestras de
tamaño par, el intervalo
. En el caso de las muestras de
tamaño par, el intervalo
![]() , se llama intervalo
mediano. A veces la mediana se define como el punto medio del
intervalo mediano.
, se llama intervalo
mediano. A veces la mediana se define como el punto medio del
intervalo mediano.
Este problema se presenta en el caso de muestras pequeñas y
para los cuantiles
![]() en los cuales
en los cuales ![]() es de la
forma
es de la
forma ![]() (más frecuente la mediana). Nosotros no lo tomaremos
en cuenta y conservaremos la definición 2.4.
Aún en muestras muy grandes, los cuantiles son poco
complicados de calcular, pues es suficiente ordenar la muestra en
orden creciente para calcular sus
estadígrafos de orden y por
tanto a la vez obtener todos los cuantiles. Ellos nos proveen una
visualización fácil de la distribución empírica. Hemos visto que
la mediana es un valor central. Para medir la
dispersión, podemos
calcular el
recorrido, que es la diferencia entre el mayor y
el menor valor. Pero este recorrido refleja más los valores
extremos que la localización de la mayor parte de los valores.
Comprendemos mejor la dispersión de una muestra por los intervalos
inter-cuartiles e
inter-deciles.
(más frecuente la mediana). Nosotros no lo tomaremos
en cuenta y conservaremos la definición 2.4.
Aún en muestras muy grandes, los cuantiles son poco
complicados de calcular, pues es suficiente ordenar la muestra en
orden creciente para calcular sus
estadígrafos de orden y por
tanto a la vez obtener todos los cuantiles. Ellos nos proveen una
visualización fácil de la distribución empírica. Hemos visto que
la mediana es un valor central. Para medir la
dispersión, podemos
calcular el
recorrido, que es la diferencia entre el mayor y
el menor valor. Pero este recorrido refleja más los valores
extremos que la localización de la mayor parte de los valores.
Comprendemos mejor la dispersión de una muestra por los intervalos
inter-cuartiles e
inter-deciles.
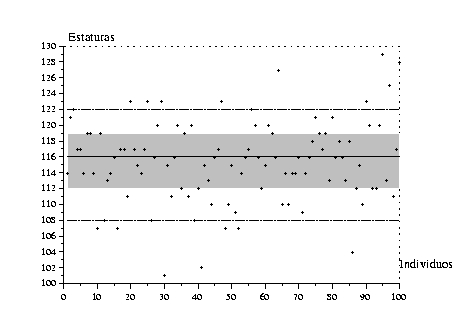
Estos intervalos forman la base de una representación muy compacta de la distribución empírica: el diagrama en caja (o caja y bigotes, box plot, box-and-whisker plot). No existe una definición general de esta representación. Ella consiste en una caja rectangular cuyos dos extremos son los cuartiles. Estos extremos se prolongan por trazos que terminan con segmentos ortogonales (los bigotes). La longitud de estos segmentos varía según el autor. Nosotros proponemos fijarlos en los deciles extremos. Representamos también la mediana por un trazo en la caja y a veces se representan también los valores extremos de la muestra. (ver la figura 8).