La
tabla de contingencia es un medio
particular de representar simultáneamente dos carácteres
observados en una misma población, si son discretos o continuos
reagrupados en clases. Los dos carácteres son ![]() e
e ![]() , el tamaño
de la muestra es
, el tamaño
de la muestra es ![]() . Las modalidades o clases de
. Las modalidades o clases de ![]() se
escribirán
se
escribirán
![]() , las de
, las de ![]() ,
,
![]() . Se
denota:
. Se
denota:

Cada fila y cada columna corresponden a una submuestra particular.
La fila de índice ![]() es la distribución en
es la distribución en
![]() , de
los individuos para los cuales el carácter
, de
los individuos para los cuales el carácter ![]() toma el valor
toma el valor
![]() . La columna de índice
. La columna de índice ![]() es la distribución sobre
es la distribución sobre
![]() , de los individuos para los cuales el carácter
, de los individuos para los cuales el carácter
![]() toma el valor
toma el valor ![]() . Dividiendo las filas y las columnas por
sus sumas, obtenemos en cada una,
distribuciones empíricas
formadas por frecuencias condicionales. Para
. Dividiendo las filas y las columnas por
sus sumas, obtenemos en cada una,
distribuciones empíricas
formadas por frecuencias condicionales. Para
![]() y
y
![]() , las denotaremos:
, las denotaremos:
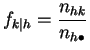 y
y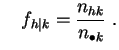
Estas
distribuciones empíricas condicionales se llaman los
perfiles-fila y perfiles-columna.
La
cuestión es estudiar la dependencia de los dos carácteres. Dos
carácteres son independientes si el valor de uno no influye sobre
la distribución de los valores del otro. Si este es el caso, los
perfiles-fila diferirán muy poco de la distribución empírica de
![]() , y los perfiles-columna de la de
, y los perfiles-columna de la de ![]() :
:
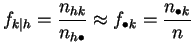 y
y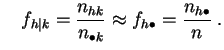
Es equivalente a decir que las frecuencias conjuntas deben estar cerca de los productos de las frecuencias marginales:
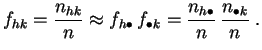
Las frecuencias conjuntas por un lado, y los productos de las
frecuencias marginales por el otro, constituyen dos distribuciones
de probabilidad sobre el conjunto producto
![]() . Una de las maneras de
cuantificar su proximidad es calcular la
distancia de chi-cuadrado
de una con respecto a la otra. En este caso particular, hablamos
de
chi-cuadrado de contingencia.
. Una de las maneras de
cuantificar su proximidad es calcular la
distancia de chi-cuadrado
de una con respecto a la otra. En este caso particular, hablamos
de
chi-cuadrado de contingencia.
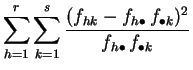 |
|||
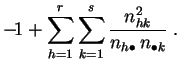 |
Demostración:
La primera expresión es la aplicación directa de la definición
2.7. Para pasar a la segunda, se desarrolla
el cuadrado.
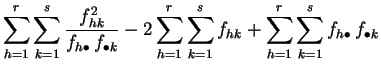 |
|||
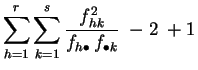 |
|||
|
La distancia de chi-cuadrado vale 0 si los dos carácteres
son independientes. Ella es máxima si existe una dependencia
sistemática. Supongamos que ![]() y
y
![]() , para una
cierta función biyectiva
, para una
cierta función biyectiva ![]() . En cada fila y en cada columna de la
tabla de contingencia una sola casilla es diferente de cero y la
distancia de chi-cuadrado vale
. En cada fila y en cada columna de la
tabla de contingencia una sola casilla es diferente de cero y la
distancia de chi-cuadrado vale ![]() .
.